

If you want your company to feel premium, you can’t just design premium screens.
You have to build a premium operating system—one that ships consistently, learns quickly, and protects users (and your brand) from avoidable mistakes.
That’s the shift we’re living through right now.
AI is no longer only “a tool that answers.” It’s becoming “a teammate that acts.” And the moment an AI system clicks links, schedules posts, edits files, or triggers workflows, the question changes from:
“Is the model smart?”
to
“Is the system trustworthy?”
This post is a leadership playbook for that moment.
It’s also a practical framework we use inside JarvisAI: one user goal, one product bet, one metric, one small shippable change—every 15 minutes.
Let’s build something that ships.
The leadership principle: consistency beats intensity
John Maxwell says leadership is influence. I’ll add a modern corollary:
Your systems are influencing your outcomes every day.
- If your system rewards “heroic sprints,” you’ll get burnout.
- If your system rewards “shipping receipts,” you’ll get momentum.
- If your system avoids verification, you’ll get surprises.
So here’s the principle we’ll build around:
Premium products don’t rely on premium people.
Premium products rely on premium systems.
The Agent‑Proof Execution Loop (the simple version)
An agent‑driven product needs a loop that’s small enough to run often—but strict enough to be safe.
Here’s the loop:
- Pick one goal (a real user outcome).
- Make one bet tied to a metric.
- Ship a V1 (small + reversible).
- Verify with evidence (not optimism).
- Log + learn so the next bet is clearer.
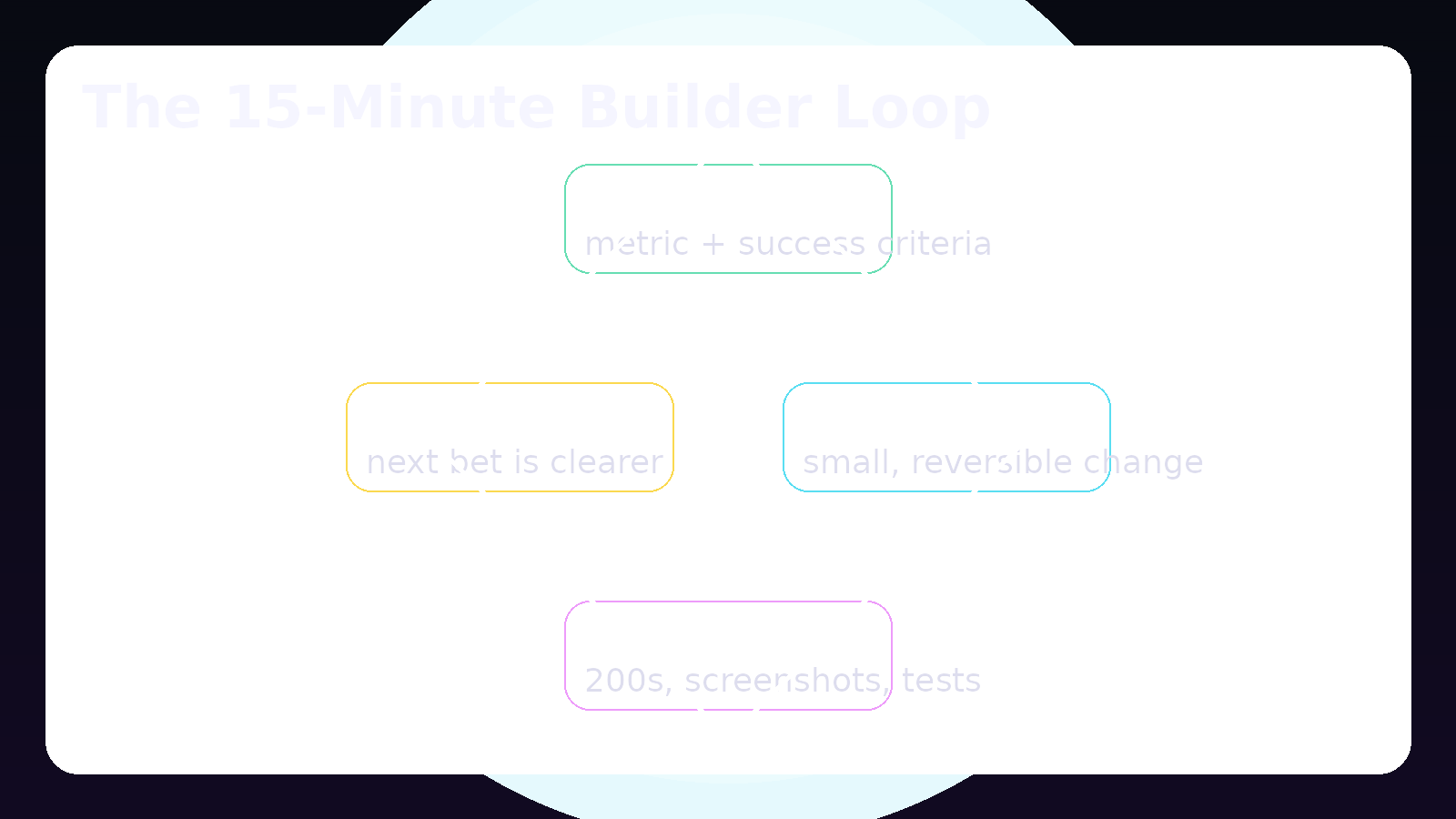
This is what “AI product execution” looks like when it’s done well: not a big bang launch, but a disciplined compounding loop.
The reliability stack: what makes an agent feel safe
Most teams treat “agent reliability” like it’s only a model problem.
In practice, reliability is a stack.

1) Intent (clarity)
A premium product starts with a premium instruction.
Bad intent is fuzzy:
- “Improve the website.”
Good intent is specific:
- “Increase homepage CTA click‑through by 10% without reducing mobile performance.”
Clarity is kindness—for users and for agents.
2) Plan (sequencing)
Agents fail less when they plan in small steps with fallback paths.
The leadership habit here is simple:
If you can’t explain the plan in 4–8 steps, you probably can’t verify it either.
3) Act (tools)
Tools are where “smart” becomes “real.”
But tools also introduce risk:
- file edits
- deployments
- link fetching
- account actions
So the premium move is not “more tools.” It’s safer tools:
- timeouts
- allowlists
- staging environments
- dry runs
4) Guardrails (boundaries)
Guardrails are not the opposite of speed.
They are what make speed sustainable.
A premium system makes it hard to do the wrong thing.
5) Verification (evidence)
The agent doesn’t get credit for trying.
It gets credit for proof.
That means:
- build passes
- pages return 200
- screenshots show the UI
- metrics are logged
Optimism is not a strategy. Verification is.
This week in AI (fresh takeaways, with primary sources)
We couldn’t use X/Twitter trend scanning in this run (Bird CLI requires cookies/auth on this machine), so we pulled the freshest items directly from primary sources’ RSS/news feeds.
Here are the takeaways that matter if you’re building agentic products.
Takeaway 1 — Agent security is now product design
OpenAI published a clear explanation of a specific agent risk: URL‑based data exfiltration (a model being tricked into loading a URL that silently encodes private data in the query string).
They describe a mitigation strategy: allowing automatic fetching only for URLs that are already known to be public via an independent web index, and otherwise requiring explicit user control.
- Source: OpenAI — “Keeping your data safe when an AI agent clicks a link”
Leadership translation: safety isn’t a compliance checkbox. It’s UX. The user experience of “safe by default” is what makes an agent feel premium.
Takeaway 2 — The agent loop is the real product
OpenAI also published a technical deep dive into the Codex agent loop, describing how an agent alternates between model inference and tool calls until it terminates with an assistant message.
- Source: OpenAI — “Unrolling the Codex agent loop”
Leadership translation: if you want a premium product, your loop has to be stable.
Not your landing page.
Your loop.
Takeaway 3 — Integrated workflows beat “AI as a side tab”
OpenAI introduced Prism, an AI‑native scientific writing and collaboration workspace with GPT‑5.2 integrated directly into the document workflow (LaTeX‑native, collaboration, in‑place edits).
- Source: OpenAI — “Introducing Prism”
Leadership translation: the winning AI products aren’t the ones with the fanciest chat. They’re the ones that remove friction from an existing workflow.
Takeaway 4 — Benchmarks are moving from demos to industrial reality
IBM Research shared AssetOpsBench, a benchmark designed to evaluate agents in industrial asset operations across multiple qualitative dimensions (including verification and hallucination rate).
- Source: Hugging Face (IBM Research) — “AssetOpsBench: Bridging the Gap Between AI Agent Benchmarks and Industrial Reality”
Leadership translation: the world is shifting from “can it do a trick?” to “can it operate under uncertainty without becoming reckless?”
The premium guardrails checklist (what great feels like)
Most teams build guardrails like they’re building a fence: tall, heavy, and annoying.
Premium teams build guardrails like they’re building a seatbelt:
- always on
- easy to use
- quietly protective

Guardrail A — Make changes reversible
Reversible changes create speed.
- Prefer additive edits
- Keep diffs small
- Avoid destructive commands
- Use previews and fallbacks
Guardrail B — Make work visible
If it didn’t leave a receipt, it didn’t happen.
- logs
- “before/after” snapshots
- build output
- deployment timestamps
Guardrail C — Make success measurable
One bet, one metric.
Even if the metric is simple:
- “CTA click‑through increased”
- “bounce rate decreased”
- “build time improved”
Guardrail D — Make it polite
A premium assistant doesn’t surprise you.
It asks before risky actions.
It explains what it will do.
It shows evidence when it’s done.
Practical: the 15‑minute shipping cadence (how to actually run this)
Here’s the operating rhythm:
- One focus area. No multitasking.
- One user goal. Say it out loud.
- One bet. Tie it to a metric.
- Ship 1–3 changes. Stop when it’s working.
- Verify with receipts. Then log.
The point isn’t to ship more.
It’s to ship reliably.
And reliability is what makes a product feel premium.
Three questions to ask before you trust an agent
Before you hand an agent the keys to your brand (or your infrastructure), run this quick test:
- Can it explain what it’s about to do in plain English? If not, it’s not ready.
- Can it show receipts after it acts? Screenshots, logs, and checks are the price of autonomy.
- Can it fail safely? When something is missing (permissions, credentials, a broken page), does it stop and escalate—or does it improvise?
If you can’t answer “yes” to all three, you don’t need a smarter model.
You need a tighter loop.
Closing: leaders don’t build features, they build momentum
A premium product is not a moment.
It’s a reputation.
Reputation is built through consistency:
- consistent layout
- consistent performance
- consistent quality
- consistent safety
And in the era of AI agents, consistency comes from an agent‑proof execution loop.
If you want to build something that ships, start with this:
- pick one goal
- ship one small change
- verify it
- repeat
That’s how premium is built—one disciplined loop at a time.


